

News Nugget
Why this Matters
Our jobs are safe – for now, since most enterprise companies still don’t know how to utilize big data or AI. Until then, understanding the culture behind big data and intelligence creation are important in shaping a more human-friendly datasphere.
Quick Takes
Why big data needs to be, well... big
The key lies right in the name “big data”. In order for machine learning to have much effect or value you need two things: clean data and lots of it (at least 1 petabyte, which is 333 of Apple’s 3-terabyte Airports, or 7,800 iPhone 7s with 128 GB storage). How many companies do you know of with at least that much data?
From an historical perspective, this explains why “big data” didn’t start taking off until 2011, becoming the giant and amorphous buzzword that it is today. Around 2011 we had smart phone adoption plus massive amounts of well-tagged image and text data come online from social media.
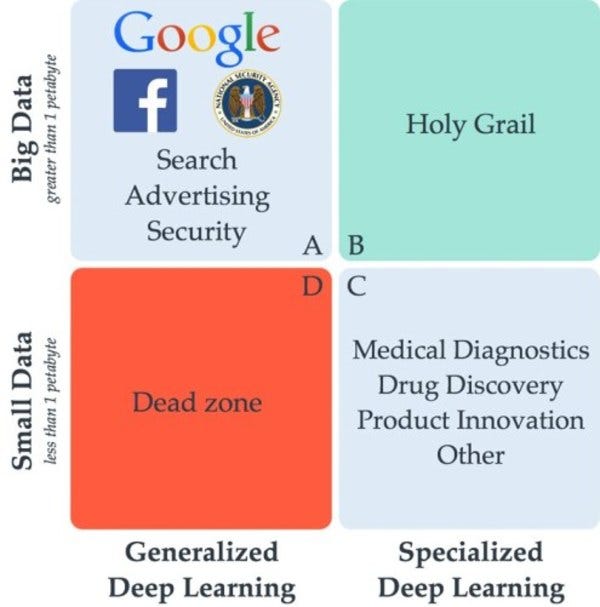
Running most ML algorithms on a small company’s datasets would be like trying to go swimming in a puddle. You just need more water. For big data, you need at least an Olympic-size swimming pool — if not an entire ocean to dive into (I guess that would deep learning).
See below for size, scale, and applications of different types of deep learning algorithms. Whispers in the wind, I’ve heard that advances are being made in applied small data, which would be great for the rest of us <1 PB data folks!
Why Big Ol' Enterprise Companies Still Can't Spin It Up
So now big data is the new trend that every enterprise company is trying to jump on and tech startups are trying to get into.
The only paying customers though, are enterprise companies, because they are the only ones with enough data. They’re the only ones with Olympic-size swimming pools in their basements. Anybody else has only bathtubs or jacuzzis.
According to Andy Palmer with Tamr and Kalyan Veeramachaneni with MIT and FeatureLabs, the problem with big data is more cultural and strategic rather than technical.
In order to use big data, machine learning, or predictive models effectively you have to start with a strategic business question, says Kalyan. That question comes from executive leadership, which for large enterprise companies, can take months to get everyone on the same page.
Once the question is formulated, it gets translated into tech speak by data scientists and executed by engineers. But scientists can’t work with dirty data. Imagine asking a librarian a question and instead of the Dewey Decimal System, the library just has piles of books on the floor. Good luck getting an answer, even from the smartest librarian.
Cleaning Up Dirty Data — No ML Required
One of the large barriers for enterprise companies, according to Tao Wu, Principal Data Scientist at Microsoft, is that they often have “legacy constraints in their way” and the culture isn’t aligned to value or use data effectively.
A lot of value can be extracted from simple data cleaning.
Large enterprise companies don’t need AI rockstars, says Andy, they need a company culture with basic awareness of statistics and data.
He recounts a project where a company was about to spend $5 million on a national advertising campaign. After running the target list against the national registry of deceased persons, they found that over 40% were dead. That would have been a $2 million loss for that company.
Even for companies that traditionally rely on logistics and data and who achieved enterprise status pre-2010, like General Electric, their databases or company structures were likely not designed with big data in mind.
Andy recounts a project with GE, which was founded in 1892 and is currently working to establish themselves as the “epicenter of the industrial internet” in Boston. In the process of adapting, they discovered that they had 3–4x fewer suppliers than they thought they had, leading to inaccurate resource allocation and a loss of millions of dollars.
Data in the Global Market
The apples hang low in the trillion dollar international telcom industry. “Simple revenue optimization in telcos is a big problem,” Andy says, regarding work done with Huawei, a large Chinese telecommunication company which overtook Ericcson in 2012.
If Huawei is hoping to move past simple revenue optimization, the success of future data solutions will depend on whether the “strategic intention [to implement data solutions is] going through the entire organization” says Tao.
Known for their customer-first culture, Huawei has achieved enormous success, but what about their data culture? With cell phones becoming a commodity and not much left in the way of design advantages, the next big plays in international telecommunications might be in data, if it isn’t already.
Changing the Culture of Data
Kalyan is working on a startup which is aimed toward making machine learning solutions easily accessible to enterprise companies. The big question, he says, is “how do you form a question?”
Like we talked about earlier, there’s a data pipeline, taking questions from the strategic executive level down to engineers, and back up again in the form of answers or Oracle-like predictions.
Predictive models are hot stuff in the data world — after all, being able to accurately predict supply and demand means more profit and less cost.
However, “like bills making it to the Congressional floor, 99.9% of predictive models never make it to use,” Kalyan says.
His startup FeatureLabs aims to make rapid prototyping of predictive models accessible to enterprise customers. With a solid understanding of enterprise culture, I’m excited to see where this company goes in the next several years.
News Nugget
Why this Matters
Our jobs are safe – for now, since most enterprise companies still don’t know how to utilize big data or AI. Until then, understanding the culture behind big data and intelligence creation are important in shaping a more human-friendly datasphere.
Quick Takes



